Resumen
A partir de abril de 2019, la funcionalidad de búsqueda de catálogo se actualizó a Elasticsearch. Esta actualización proporciona una serie de beneficios, entre los que se encuentran la relevancia y la precisión mejoradas, y el rendimiento drásticamente mejorado: el tiempo de respuesta es mucho más consistente y generalmente el doble de rápido. Esta nueva funcionalidad afectará la API de CMS, la API de reproducción, la búsqueda interactiva de Studio y los métodos de búsqueda de catálogo.
Si bien Brightcove ha invertido una cantidad sustancial de esfuerzo en hacer que los resultados de Elasticsearch sean consistentes, existen diferencias y existe una pequeña posibilidad de que si ha codificado dependencias específicas en los resultados de búsqueda, es posible que su integración no se comporte como se esperaba.
Diferencias e impacto en los resultados de búsqueda
Al estudiar el impacto potencial, Brightcove descubrió que más del 90% de las búsquedas arrojan resultados que coinciden en términos de la cantidad de resultados devueltos. Este es un indicador de que los resultados esperados no deben ser lo suficientemente diferentes como para causar problemas con las integraciones de API.
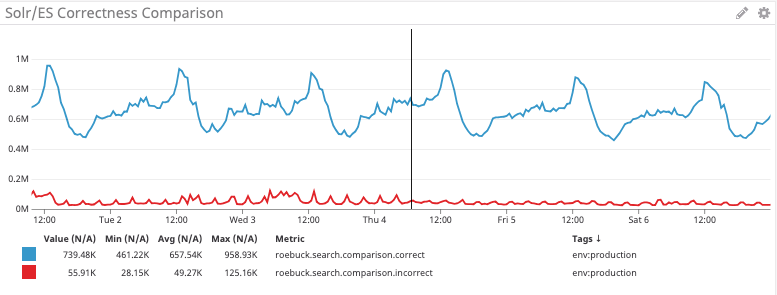
Este gráfico muestra el número de resultados de búsqueda que coinciden exactamente con el número de resultados entre los dos sistemas en azul y los que difieren en número en rojo.
Como parte de nuestra implementación, Elasticsearch ya ha proporcionado todas las búsquedas predeterminadas, esas búsquedas en la cadena vacía, desde hace varios meses, por lo que los usuarios ya están viendo y usando los resultados de Elasticsearch sin problemas.
Sin embargo, existen limitaciones a lo que podemos aprender de este tipo de comparación. En el mejor de los casos, solo podemos inferir la intención de una búsqueda en particular y los datos del catálogo son fluidos.
Diferencias conocidas
Las diferencias a continuación son en gran parte fundamentales, o el resultado de decisiones tomadas después de un análisis extenso de los resultados de búsqueda; son imposibles de eliminar por completo.
Derivado
derivación es el proceso de reducir las palabras flexionadas (o, a veces, derivadas) a su raíz de la palabra , base o raíz forma — generalmente una forma de palabra escrita.
Un stemmer para inglés que opera en el tallo. gato debe identificar tal instrumentos de cuerda como gatos , felino y malicioso. Un algoritmo de derivación también podría reducir las palabras pesca , pescado y pescador al tallo pez. La raíz no necesita ser una palabra, por ejemplo, el algoritmo de Porter reduce argumentar , argumentó , argumenta , discutiendo y Argos al tallo argumentar.
Nuestra búsqueda actual utiliza el lematizador Lancaster (Paice / Husk), este algoritmo generalmente se considera demasiado agresivo; esto da como resultado una falta de distinción, por ejemplo encendedor y luz sería considerado como el mismo término en Lancaster.
Elasticsearch utiliza un algoritmo más reciente y mucho menos agresivo (Porter2) que ha ganado una amplia adopción en la industria y generalmente se considera una mejora significativa (Lancaster ahora es poco común). El cambio de lematizador potencialmente impacta una proporción significativa (~ 35%) de búsquedas: eso no quiere decir que los resultados voluntad ser diferente, solo que ellos podría ser diferente, pero en general esto debería ser para mejor: dicho esto, algunos subconjuntos de clientes pueden depender del comportamiento anterior.
Relevancia
Nuestra búsqueda actual parece tener una normalización de TF más estricta. Esto provoca una clasificación de relevancia diferente para los términos que se encuentran en campos más grandes (es decir, existente considera que la coincidencia es menos relevante ya que le da menos peso al término ya que es más pequeño en relación con la longitud del documento).
Caracteres especiales
Los caracteres especiales se eliminan dentro de nuestra búsqueda existente, esto prácticamente equivale a eliminar la puntuación y los caracteres relacionados; en lugar de eliminarlos, generalmente los escapamos en Elasticsearch, por lo que existe la posibilidad de que una búsqueda los tenga en cuenta.
Manejo de términos
Las consultas de búsqueda existentes realizan "suavizado de términos" mientras que en Elasticsearch descartamos términos con formato incorrecto, considere esta búsqueda con un tags: término: q=tags: state:ACTIVE
- Existente :
tags:state:ACTIVE— buscar videos con una etiqueta destate:ACTIVE - Elasticsearch :
state:ACTIVE- suelte el término vacío
Hay una serie de casos extremos sutiles relacionados con el manejo de la puntuación colgante y las consultas que generalmente tienen un formato incorrecto, intentamos producir lo que creemos que la consulta pretendía ser, pero en estos casos, lamentablemente, estamos adivinando lo que podría haber pretendido un usuario ( cuando en realidad deberíamos haber devuelto un error que les permitiera refinar su búsqueda)
Solo jugable
Existen dos mecanismos para restringir una búsqueda a los videos que se pueden reproducir actualmente: la consulta puede incluir una bandera o la consulta en sí puede requerir algún aspecto de la reproducción.
- Existente: se consulta en función del valor de un campo que se actualiza
- Elasticsearch: esto se consulta en función de los rangos de fechas calculados
Elasticsearch generalmente debería ser más preciso y producir mejores resultados (hay un retraso asociado con el mecanismo existente y el mecanismo de mantenimiento de banderas no es del todo confiable).
Precisión del índice
El índice Elasticsearch es 'más reciente' que el índice existente y tiende a reflejar las actualizaciones más rápido; este no es siempre el caso, pero en general, la experiencia con Elasticsearch es que los resultados reflejarán con mayor precisión el estado de los datos del catálogo subyacente. Tanto el existente como Elasticsearch son sistemas distribuidos y, por lo tanto, no son del todo coherentes en los resultados que devuelven: una consulta repetida en cualquiera de los sistemas puede devolver resultados diferentes (especialmente en el caso de que haya varias operaciones de eliminación que se ejecutan simultáneamente).
Los resultados de búsqueda existentes cambian según el estado del fragmento al que se asigna una cuenta; el estado global de un fragmento en particular puede afectar (y lo hace) los resultados de cualquier consulta en particular: Elasticsearch no tiene esta deficiencia.
Ejemplos
Ejemplo 1
Digamos que hay dos videos con los siguientes títulos:
Video#1: has the title “Don’t look into the light”
Video#2: has the title “Using a lighter to make a campfire”
El usuario desea devolver todos los videos que deben tener la palabra “light”. Con la API de CMS, la consulta tendría el siguiente aspecto:
q=%2Blight or q=+light
Con la búsqueda existente, esto devolverá ambos videos en el orden:
Video#2 - “Using a lighter to make a campfire”
Video#1 - “Don’t look into the light”
Hay dos problemas con esto:
- Relevancia: El pedido es incorrecto. "No mires a la luz" (video n. ° 2) debe aparecer antes de "Usar un encendedor para hacer una fogata" (video n. ° 1)
- Precisión: "Usar un encendedor para hacer una fogata" ni siquiera debería aparecer en el conjunto de resultados, ya que la palabra "luz" no aparece en absoluto en el título del video.
Con Elasticsearch, esto devolverá solo el video uno:
Video#1 - “Don’t look into the light”
Esto supone una mejora porque:
- Relevancia: El pedido es correcto.
- Precisión: Solo se devuelve el video uno, ya que es el único video con la palabra "light" en el título.
Ejemplo 2
Como se describe en nuestro Documentación de la API de CMS para derivación , se admite la lematización, pero no las búsquedas parciales de palabras. Digamos que hay 5 videos con los siguientes títulos:
Video#1 - "Parking Ban Announced"
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Video#4 - "Bank Holiday"
Video#5 - "Bandit Captured"
El usuario desea devolver todos los videos que deben tener la palabra prohibición en el campo de nombre. Con la API de CMS, la consulta tendría el siguiente aspecto:
q=%2Bname%3Aban or q=+name:ban
La expectativa es que "Prohibir", "Prohibir" y "Prohibir" producirían resultados de búsqueda, ya que "Prohibir" es una raíz de los tres.
Sin embargo, con el sistema de búsqueda actual, esto devolverá los cinco videos en este orden:
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Video#1 - "Parking Ban Announced"
Video#4 - "Bank Holiday"
Video#5 - "Bandit Captured"
Nuevamente, hay dos problemas con esto:
- Relevancia: El pedido es incorrecto. "Prohibición de estacionamiento anunciada" debería ser el primer video que se devuelva, ya que tiene la palabra "Prohibición".
- Precisión: "Bank Holiday" y "Bandit Captured" no deben devolverse en absoluto, ya que "Ban" no es parte de la palabra "Bank" o "Bandit".
Con Elasticsearch, los resultados se ven así:
Video#1 - "Parking Ban Announced"
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Esto supone una mejora porque:
- Relevancia: El pedido es correcto.
- Precisión: Solo se muestran los videos con la raíz de la palabra "Prohibir" ("Prohibir", "Prohibir" y "Prohibir").